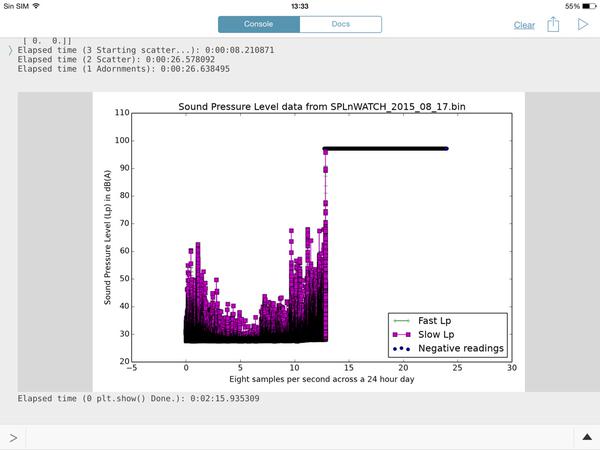
Here is a short sample of the values read by your script in Array Mode. Observe the zero values at the end.
(50.56001281738281, 53.25138854980469), (51.46320724487305, 59.16133117675781), (53.85163116455078, 56.33137512207031), (54.70978546142578, 54.6609001159668), (55.20241165161133, 47.02310562133789), (55.262977600097656, 40.11175537109375), (54.45186996459961, 43.808773040771484), (54.05076217651367, 42.50151824951172), (53.665225982666016, 54.5957145690918), (53.8406867980957, 65.96211242675781), (58.009944915771484, 65.0105972290039), (59.889801025390625, 59.607154846191406), (60.222530364990234, 56.390960693359375), (60.41679763793945, 54.57362747192383), (60.55101776123047, 41.55317687988281), (60.54636001586914, 40.97874450683594), (60.54383850097656, 46.896514892578125), (60.42774200439453, 45.11729049682617), (57.88348388671875, 49.7500114440918), (53.61359786987305, 46.01418685913086), (50.81377410888672, 36.51190185546875), (48.24237823486328, 31.083229064941406), (44.919986724853516, 32.971107482910156), (44.69907760620117, 46.87627410888672), (45.31845474243164, 39.48908233642578), (44.62737274169922, 35.4039192199707), (44.04755401611328, 34.72141647338867), (41.45051956176758, 34.2315673828125), (39.6866569519043, 33.11891174316406), (39.542598724365234, 50.92300796508789), (43.85606002807617, 34.235633850097656), (43.871002197265625, 40.384735107421875), (42.935977935791016, 52.999149322509766), (46.3834228515625, 52.6627311706543), (48.203895568847656, 57.949790954589844), (51.57520294189453, 52.208770751953125), (52.15311050415039, 45.712528228759766), (52.26800537109375, 50.851497650146484), (52.261497497558594, 46.12493133544922), (52.383358001708984, 84.88561248779297), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0), (0.0, 0.0)

{kind=link}